一、Linux复习
0.网络配置
1.ip addr 查看IP
2.xshell远程连接
xshell和xsftp下载地址 https://www.xshell.com/zh/free-for-home-school/
虚拟机下载地址: https://www.vmware.com
CentOs官网下载
官网:https://www.centos.org/
1).查看自己网段和网关
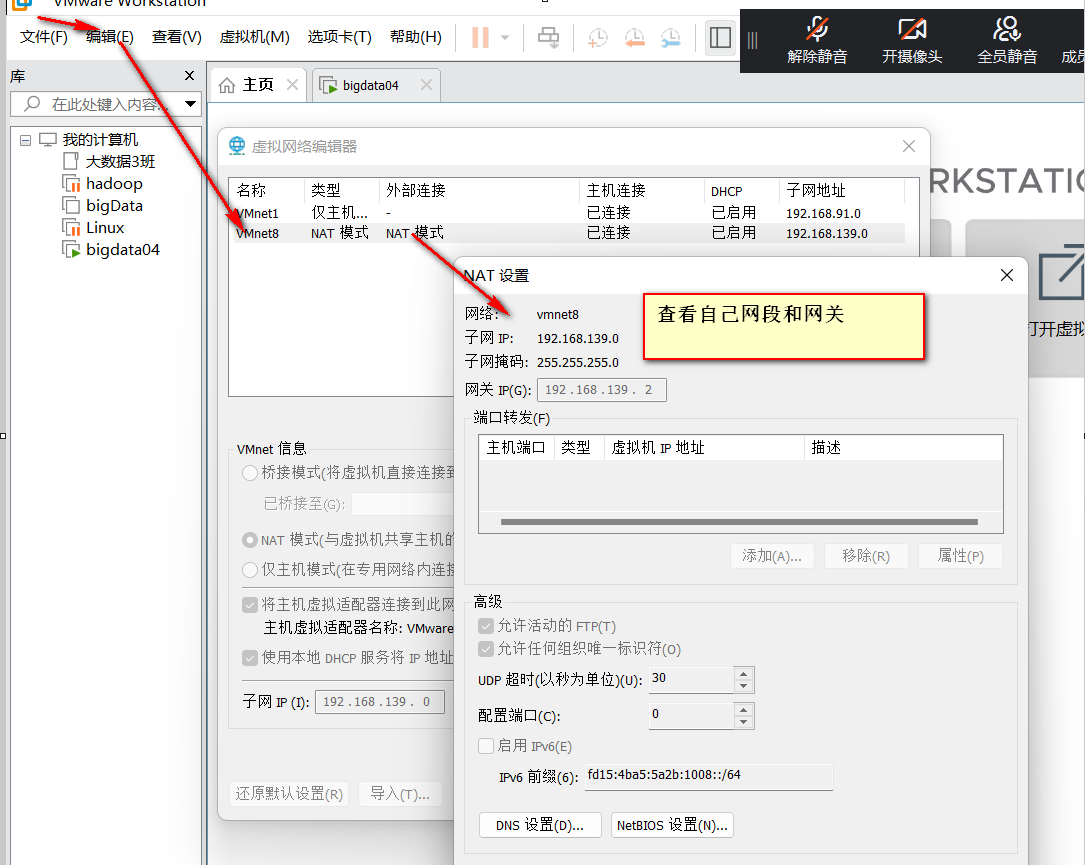
2).修改配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#添加IP地址和自己网段相同 老师是192.168.139网段
IPADDR=192.168.139.10
#添加网关
GATEWAY=192.168.139.2
#添加域名解析器
DNS1=192.168.139.2
#修改BOOTPROTO="dhpc" 为 static
BOOTPROTO="static"
#修改ONBOOT="yes"
ONBOOT="yes" #系统启动的时候网络接口是否有效(yes/no)
3).重启网络
service network restart
4).关闭防火墙
(1)查看防火墙服务的状态
systemctl status firewalld
(2)停止防火墙服务
systemctl stop firewalld
(3)启动防火墙服务
开机自动关闭防火墙
systemctl disable firewalld.service
yum install -y epel-release
yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git zip unzip
-- 设置固定ip地址,重启网络
-- 用shell工具连接Linux
-- 关防火墙
-- 通过yum安装方式安装必要的软件
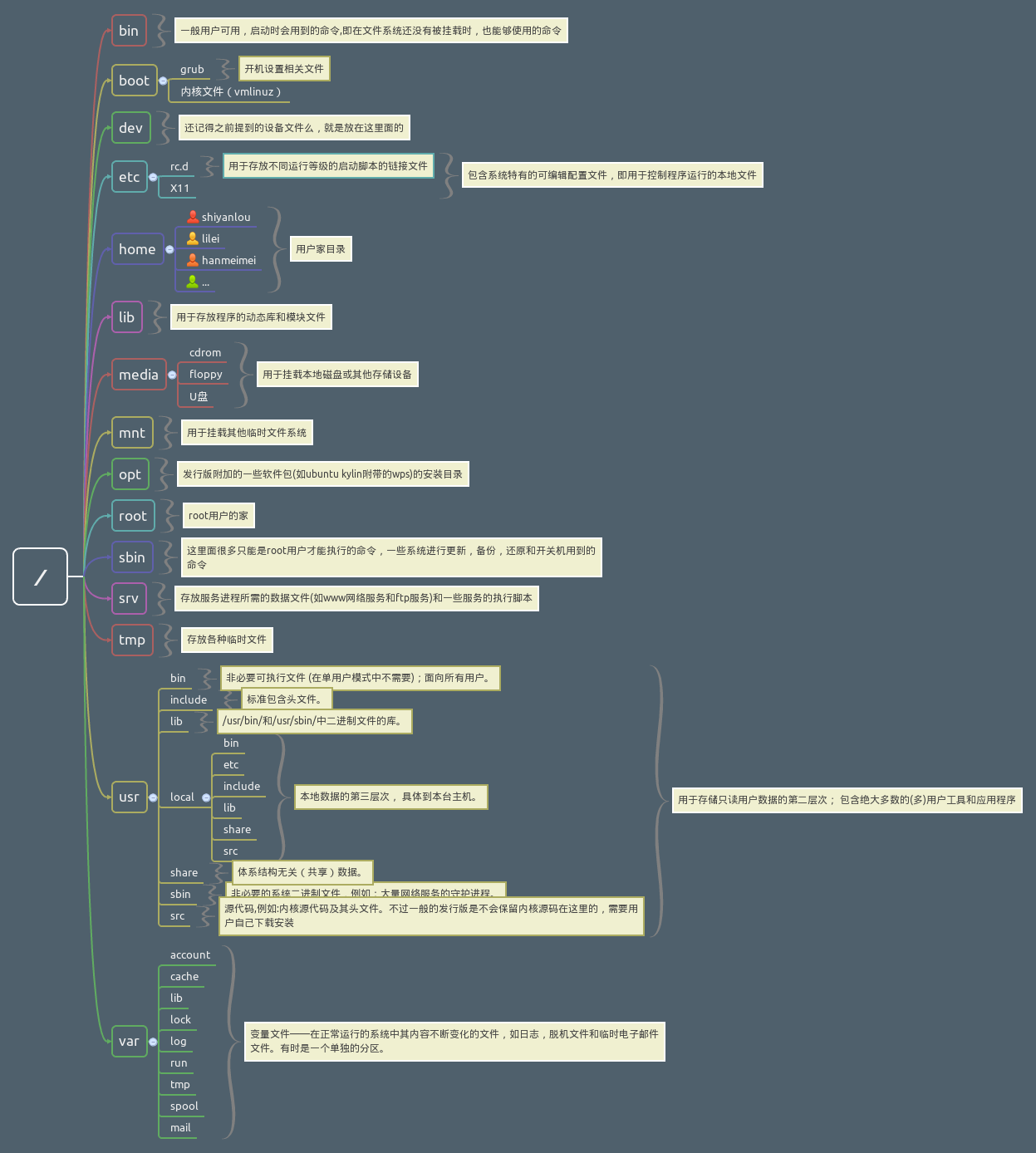
1.Linux目录结构
-
/:根目录
-
boot:bootstrap 系统启动的地方
-
bin:binary 命令(可执行文件),一般用户可用,启动时会用到的命令
-
sbin:system binary 多数是 root 才能用的命令
-
dev:device 设备文件
-
etc:配置文件
-
lib:library 程序动态链接库
-
media:用于挂载本地磁盘或其他存储设备
-
mnt:mount 挂载,挂载其他临时文件系统
-
opt:optional 可选的软件包的安装目录
-
srv:service 服务,服务进程所需的数据文件和一些服务的执行脚本
-
tmp:temporary,临时的,存放各种临时文件
-
root:超级用户的家
-
home:普通用户的家在 home 下建立,如/home/zhengwei 就是 zhengwei 的家
-
usr:user shared resource 或 unix software resource,绝大多数用户工具和应用程序
-
var:variable,可变的,存放不断变化的文件
2.VI/VIM编辑器
VI是Unix操作系统和类Unix操作系统中最通用的文本编辑器。
VIM编辑器是从VI发展出来的一个性能更强大的文本编辑器。可以主动的以字体颜色辨别语法的正确性,方便程序设计。VIM与VI编辑器完全兼容。
2.1一般模式
以vi打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中, 你可以使用『上下左右』按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容, 也可以使用『复制、粘贴』来处理你的文件数据。
常用语法
| 语法 | 功能描述 |
|---|
| yy | 复制光标当前一行 |
| y数字y | 复制一段(从第几行到第几行) |
| p | 箭头移动到目的行粘贴 |
| u | 撤销上一步 |
| dd | 删除光标当前行 |
| d数字d | 删除光标(含)后多少行 |
| x | 剪切一个字母,相当于del |
| X | 剪切一个字母,相当于Backspace |
| yw | 复制一个词 |
| dw | 删除一个词 |
| shift+6(^) | 移动到行头 |
| shift+4 ($) | 移动到行尾 |
| 1+shift+g | 移动到页头,数字 |
| shift+g | 移动到页尾 |
| 数字+shift+g | 移动到目标行 |
2.2编辑模式
在一般模式中可以进行删除、复制、粘贴等的动作,但是却无法编辑文件内容的!要等到你按下『i, I, o, O, a, A』等任何一个字母之后才会进入编辑模式。
注意了!通常在Linux中,按下这些按键时,在画面的左下方会出现『INSERT或 REPLACE』的字样,此时才可以进行编辑。而如果要回到一般模式时, 则必须要按下『Esc』这个按键即可退出编辑模式。
1)进入编辑模式
| 按键 | 功能 |
|---|
| i | 当前光标前 |
| a | 当前光标后 |
| o | 当前光标行的下一行 |
| I | 光标所在行最前 |
| A | 光标所在行最后 |
| O | 当前光标行的上一行 |
2)退出编辑模式
按『Esc』键 退出编辑模式,之后所在的模式为一般模式。
2.3指令模式
在一般模式当中,输入『 : / ?』3个中的任何一个按钮,就可以将光标移动到最底下那一行。
在这个模式当中, 可以提供你『搜寻资料』的动作,而读取、存盘、大量取代字符、离开 vi 、显示行号等动作是在此模式中达成的!
1)基本语法
| 命令 | 功能 |
|---|
| :w | 保存 |
| :q | 退出 |
| :! | 强制执行 |
| /要查找的词 | n 查找下一个,N 往上查找 |
| :noh | 取消高亮显示 |
| :set nu | 显示行号 |
| :set nonu | 关闭行号 |
| :%s/old/new/g | 替换内容 /g 替换匹配到的所有内容 |
2)实操练习
(1)强制退出
:q!
2.4课堂练习
1)创建hello.java
2)完成老师课堂的操作
3.文件目录常用命令
3.1.pwd 显示当前工作目录的绝对路径
pwd:print working directory 打印工作目录
1)基本语法
pwd (功能描述:显示当前工作目录的绝对路径)
2)实操练习
(1)显示当前工作目录的绝对路径
[root@hadoop software]# pwd
/opt/software
ls 列出目录的内容
ls:list 列出目录内容
1)基本语法
ls [选项] [目录或是文件]
2)选项说明
| 选项 | 功能 |
|---|
| -a | 全部的文件,连同隐藏档( 开头为 . 的文件) 一起列出来(常用) |
| -l | 长数据串列出,包含文件的属性与权限等等数据;(常用)等价于“ll” |
3)显示说明
每行列出的信息依次是: 文件类型与权限 链接数 文件属主 文件属组 文件大小用byte来表示 建立或最近修改的时间 名字
4)实操练习
(1)查看当前目录的所有内容信息
[root@hadoop software]# ls -al
总用量 826140
drwxr-xr-x. 2 root root 4096 8月 18 11:35 .
drwxr-xr-x. 6 root root 4096 8月 18 11:31 ..
-rw-r--r--. 1 root root 312850286 8月 6 15:33 apache-hive-3.1.2-bin.tar.gz
-rw-r--r--. 1 root root 338075860 8月 4 17:09 hadoop-3.1.3.tar.gz
-rw-r--r--. 1 root root 195013152 8月 4 17:28 jdk-8u212-linux-x64.tar.gz
-rw-r--r--. 1 root root 9224 9月 12 2016 mysql57-community-release-el7-9.noarch.rpm
3.2cd 切换目录
cd:Change Directory切换路径
1)基本语法
cd [参数]
2)参数说明
| 参数 | 功能 |
|---|
| cd 绝对路径 | 切换路径 |
| cd相对路径 | 切换路径 |
| cd ~或者cd | 回到自己的家目录 |
| cd - | 回到上一次所在目录 |
| cd .. | 回到当前目录的上一级目录 |
| cd -P | 跳转到实际物理路径,而非快捷方式路径 |
3)实操练习
(1)使用绝对路径切换到opt目录
[root@hadoop ~]# cd /opt/
(2)使用相对路径切换到software目录
[root@hadoop opt]# cd software/
(3)表示回到自己的家目录,亦即是 /root 这个目录
[root@hadoop software]# cd ~
(4)cd- 回到上一次所在目录
[root@hadoop ~]# cd -
/opt/software
(5)表示回到当前目录的上一级目录,/opt/software上一级目录的意思;
[root@hadoop software]# cd ..
3.3mkdir 创建一个新的目录
mkdir:Make directory 建立目录
1)基本语法
mkdir [选项] 要创建的目录
2)选项说明
3)实操练习
(1)创建一个目录
[root@hadoop ~]# mkdir bigdata03
[root@hadoop ~]# mkdir bigdata03/group1
(2)创建一个多级目录
[root@hadoop ~]# mkdir -p bigdata04/group1
3.4rmdir 删除一个空的目录
rmdir:Remove directory 移动目录
1)基本语法
rmdir 要删除的空目录
2)实操练习
(1)删除一个空的文件夹
[root@hadoop ~]# rmdir bigdata03/group1/
3.5 touch 创建空文件
1)基本语法
touch 文件名称
2)实操练习
[root@hadoop ~]# touch bigdata03/group1/zhangsan.txt
3.6 cp 复制文件或目录
1)基本语法
cp [选项] source dest (功能描述:复制source文件到dest)
1)选项说明
3)参数说明
4)实操练习
(1)复制文件
[root@hadoop ~]# cp bigdata03/group1/zhangsan.txt bigdata04/group1/
(2)递归复制整个文件夹
cp -r bigdata03/group1/ bigdata04/
3.7rm删除文件或目录
1)基本语法
rm [选项] deleteFile (功能描述:递归删除目录中所有内容)
2)选项说明
| 选项 | 功能 |
|---|
| |
| -r | 递归删除目录中所有内容 |
| -f | 强制执行删除操作,而不提示用于进行确认。 |
| -v | 显示指令的详细执行过程 |
3)实操练习
(1)删除目录中的内容
[root@hadoop ~]# rm bigdata03/group1/zhangsan.txt
(2)递归删除目录中所有内容
[root@hadoop ~]# rm -rf bigdata03/
3.8mv 移动文件与目录或重命名
1)基本语法
(1)mv oldFile newFile
2)实操练习
(1)重命名
[root@hadoop group1]# mv zhangsan.txt lisi.txt
(2)移动文件
[root@hadoop group1]# mv lisi.txt ../group2/
3.9cat 查看文件内容
查看文件内容,从第一行开始显示。
1)基本语法
cat [选项] 要查看的文件
2)选项说明
3)经验技巧
一般查看比较小的文件,一屏幕能显示全的。
4)实操练习
(1)查看文件内容并显示行号
[root@hadoop group1]# cat -n zhangsan.txt
3.10tail 输出文件尾部内容
tail用于输出文件中尾部的内容,默认情况下tail指令显示文件的后10行内容。
1)基本语法
(1)tail 文件 (功能描述:查看文件尾部10行内容)
(2)tail -n 5文件 (功能描述:查看文件尾部5行内容,5可以是任意行数)
(3)tail -f 文件 (功能描述:实时追踪该文档的所有更新)
2)选项说明
| 选项 | 功能 |
|---|
| -n<行数> | 输出文件尾部n行内容 |
| -f | 显示文件最新追加的内容,监视文件变化 |
3)实操练习
(1)查看文件尾3行内容
[root@hadoop group1]# tail -n 3 zhangsan.txt
(2)实时追踪该档的所有更新
[root@hadoop group1]# tail -f zhangsan.txt
3.11 > 输出重定向和 >> 追加
1)基本语法
(1)ls -l > 文件 (功能描述:列表的内容写入文件a.txt中(覆盖写))
(2)ls -al >> 文件 (功能描述:列表的内容追加到文件aa.txt的末尾)
(3)cat 文件1 > 文件2 (功能描述:将文件1的内容覆盖到文件2)
(4)echo “内容” >> 文件
2)实操练习
(1)将ls查看信息写入到文件中
[root@hadoop group1]# ls -al >lisi.txt
(2)将ls查看信息追加到文件中
[root@hadoop group1]# ls -al >>lisi.txt
(3)采用echo将hello单词追加到文件中
[root@hadoop group1]# echo hello >>lisi.txt
3.12 history 查看已经执行过历史命令
1)基本语法
history (功能描述:查看已经执行过历史命令)
2)实操练习
(1)查看已经执行过的历史命令
[root@hadoop group1]# history
4.压缩解压常用命令
4.1 gzip/gunzip 压缩
1)基本语法
gzip 文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件)
gunzip 文件.gz (功能描述:解压缩文件命令)
2)经验技巧
(1)只能压缩文件不能压缩目录
(2)不保留原来的文件
(3)同时多个文件会产生多个压缩包
3)实操练习
(1)gzip压缩
[root@hadoop ~]#ll
test.java
[root@hadoop ~]# gzip test.java
[root@hadoop ~]#ll
test.java.gz
(2)gunzip解压缩文件
[root@hadoop ~]# gunzip test.java.gz
[root@hadoop ~]# ls
test.java
4.2zip/unzip 压缩
1)基本语法
zip [选项] XXX.zip 将要压缩的内容 (功能描述:压缩文件和目录的命令)
unzip [选项] XXX.zip (功能描述:解压缩文件)
2)选项说明
| unzip选项 | 功能 |
|---|
| -d<目录> | 指定解压后文件的存放目录 |
**3)**经验技巧
zip 压缩命令在window/linux都通用,可以压缩目录且保留源文件。`
**4)**实操练习
(1)压缩 test1.java 和test2.java,压缩后的名称为test.zip
yum install zip unzip
[root@hadoop ~]# zip test.zip test1.java test2.java
adding: test1.java (stored 0%)
adding: test2.java (stored 0%)
[root@hadoop ~]# ll
test1.java
test2.java
test.zip
(2)解压 test.zip
[root@hadoop ~]#unzip test.zip
(3)解压test.zip到指定目录-d
[root@hadoop ~]#unzip test.zip -d /opt
4.3 tar 打包
1)基本语法
tar [选项] XXX.tar.gz 将要打包进去的内容 (功能描述:打包目录,压缩后的文件格式.tar.gz)
2)选项说明
| 选项 | 功能 |
|---|
| -c | 产生.tar打包文件 |
| -v | 显示详细信息 |
| -f | 指定压缩后的文件名 |
| -z | 打包同时压缩 |
| -x | 解包.tar文件 |
| -C | 解压到指定目录 |
3)实操练习
(1)压缩多个文件
[root@hadoop ~]#tar -zcvf test.tar.gz test1.java test2.java
[root@hadoop ~]#ls
test1.java test2.java test.tar.gz
(2)压缩目录
[root@hadoop ~]# tar -zcvf bigdata03.tar.gz bigdata03/
(3)解压到当前目录
[root@hadoop ~]# tar -zxvf test.tar.gz
(4)解压到指定目录
[root@hadoop ~]# tar -zxvf test.tar.gz -C /opt
5.Linux 文件类型和权限
首先,我们用命令 ls -alh ~ 来查看一下文件的详细信息。
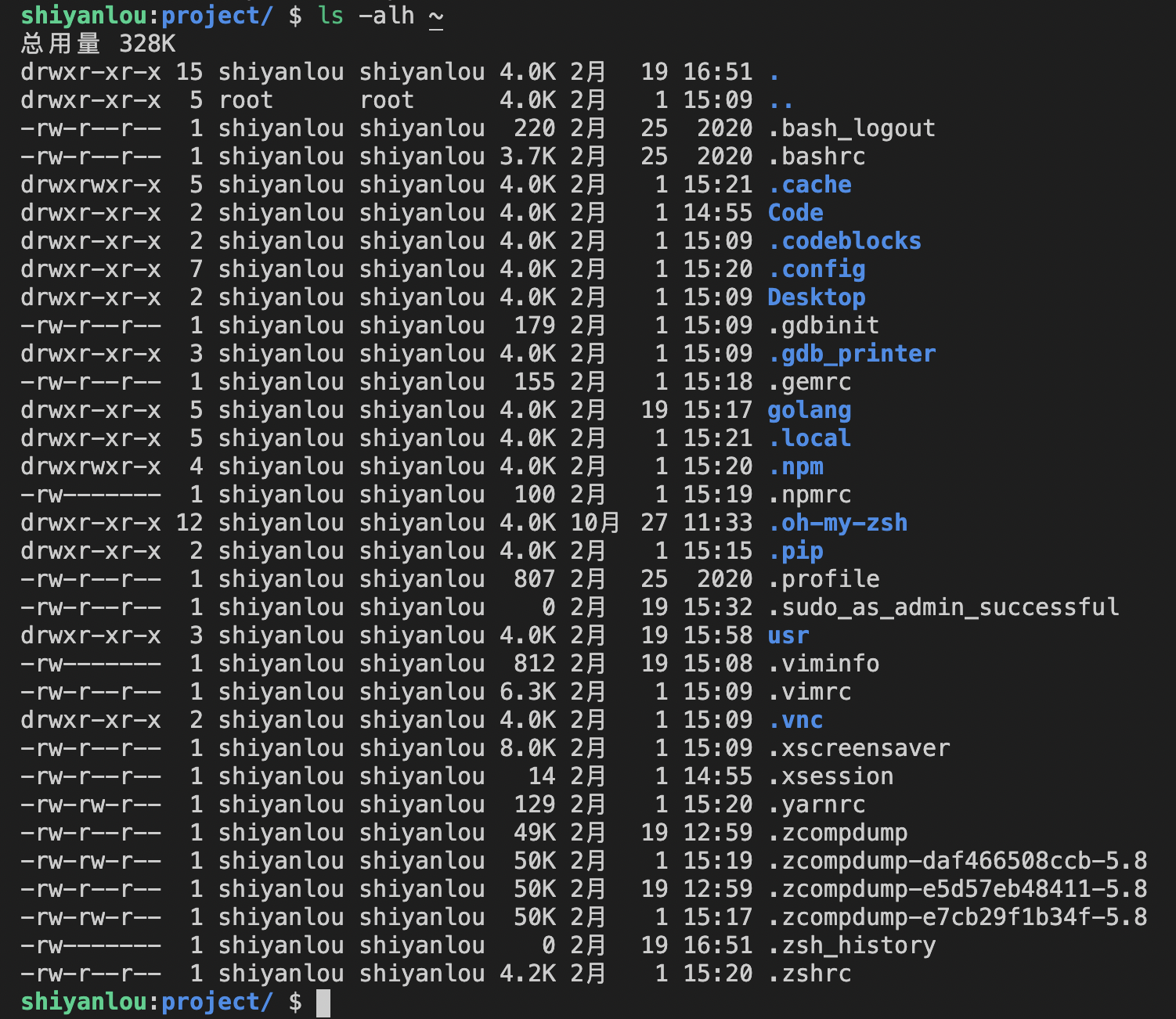
从屏幕打印出来的信息,以空格为分组标志,从左到右依次表示:
文件类型和权限、硬链接数、所有者、所属组、文件大小、最后修改时间、文件名。
还有一个比较重要的概念就是 Linux 里面一切皆文件,你可能暂时不能理解这个概念,不过没关系,只需要记住这个概念即可。
5.1文件类型
第一个字符代表的就是文件的类型,文件类型主要分为以下 7 种,大家只需要了解前三种即可,后面的文件一般不常使用:
-
普通文件 -:文本文件、数据文件、可执行程序等等都可作为普通文件存储。
-
目录 d:目录中按照名字来对其它文件进行引用。
-
符号链接 l:也叫做软链接,通过名字指向文件。
字符设备文件 c:字符设备文件让相关的驱动程序作为输入输出的缓冲。
块设备文件 b:块设备文件由处理块数据的 I/O 驱动程序使用,同时让内核提供缓冲。
本地域套接口 s:实现进程间通信的连接,本地域套接口由系统调用 socket 创建,用 rm 或 unlink 删除。
有名管道(FIFO)p:让运行在同一主机上的两个进程相互通信,和 socket 相似,用 mknod 创建,用 rm 来删除。
5.2文件权限
除去文件类型外,后面的字符,以三个为一组,且均为 rwx 的三个参数组合,代表了 Linux 的 读、写、执行 三种权限控制。r 代表可读(read)、w 代表可写(write)、x 代表可执行(execute)。要注意的是,这三个权限的位置不会改变,如果没有权限,就会出现减号 -。
其中三位一组分别是 所有者的权限(U,即 user)、所属组的权限(G,即 group)、其他用户的权限(O,即 other) 。
5.3权限编码
| 数字 | 字符 | 文件/目录 |
|---|
| 4 | r | 查看文件内容/查看目录下的文件或目录名称 |
| 2 | w | 修改文件内容/在目录下增删改 |
| 1 | x | 执行一些程序或脚本/可以用命令切换目录 |
| 八进制 | 二进制 | 权限 |
|---|
| 0 | 000 | --- |
| 1 | 001 | --x |
| 2 | 010 | -w- |
| 3 | 011 | -wx |
| 4 | 100 | r-- |
| 5 | 101 | r-x |
| 6 | 110 | rw- |
| 7 | 111 | rwx |
5.3.1chmod 改变权限
chmod 命令用于改变 Linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令修改权限有三种用法。一种是字符形式来设置,一种是包含操作符表达式的文字设置,另一种是包含数字的数字设置。
1)基本语法
chmod +权限+文件或者目录
2)实操练习
(1)使用字符形式修改文件为全部可读、可写、可执行权限
[root@hadoop ~]# chmod u=rwx,g=rwx,o=rwx test1.java
(2)使用操作符形式修改权限修改文件为u可读、可写、可执行,g可读、可写权限,o可读权限
[root@hadoop ~]# chmod u+rwx,g-x,o-wx test1.java
(3)使用数字修改权限
# 修改文件权限为 `rwxrwxrwx`
chmod 777 install.log
# 修改文件权限为 `rwx------`
chmod 700 install.log
# 修改文件权限为 `rwxr-xr-x`
chmod 755 install.log
5.3.2chown 改变所有者
chown 命令是 change owner(改变所有人) 的缩写,主要用于改变文件或者目录的所有权,语法和 chmod 类似。chown 需要超级用户 root 的权限才能执行此命令。
1)基本语法
chown [选项] [最终用户] [文件或目录] (功能描述:改变文件或者目录的所有者)
2)选项说明
3)实操练习
(1)修改文件所有者
[root@hadoop ~]# chown lzh test1.java
(2)递归改变文件所有者和所有组
[root@hadoop ~]# chown -R lzh:root bigdata03/
5.3.3chgrp 改变所有组
1)基本语法
chgrp [最终用户组] [文件或目录] (功能描述:改变文件或者目录的所属组)
2)实操练习
(1)修改文件的所属组
[root@hadoop ~]# chgrp -R lzh test1.java
6.Linux用户管理
6.1useradd 添加新用户
1)基本语法
useradd 用户名 (功能描述:添加新用户)
useradd -g 组名 用户名 (功能描述:添加新用户到某个组)
2)实操练习
(1)添加一个用户
[root@hadoop ~]# useradd lzh
[root@hadoop ~]# ll /home/
6.2 passwd 设置用户密码
1)基本语法
passwd 用户名 (功能描述:设置用户密码)
2)实操练习
(1)设置用户的密码
[root@hadoop ~]# passwd 123456
6.3 id查看用户是否存在
1)基本语法
id 用户名
2)实操练习
(1)查看用户是否存在
[root@hadoop ~]# id lzh
6.4 su 切换用户
su: swith user 切换用户
1)基本语法
su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量)
su - 用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限)
**2)**实操练习
(1)切换用户
[root@hadoop ~]# su lzh
[lzh@hadoop root]$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk1.8.0_212/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/root/bin:/opt/jdk1.8.0_212/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/opt/jdk1.8.0_212/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/opt/jdk1.8.0_212/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin
[root@hadoop ~]# su - lzh
[lzh@hadoop root]$ echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/jdk1.8.0_212/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/home/lzh/.local/bin:/home/lzh/bin
6.5 userdel 删除用户
1)基本语法
(1)userdel 用户名 (功能描述:删除用户但保存用户主目录)
(2)userdel -r 用户名 (功能描述:用户和用户主目录,都删除)
2)选项说明
| 选项 | 功能 |
|---|
| -r | 删除用户的同时,删除与用户相关的所有文件。 |
3)实操练习
(1)删除用户但保存用户主目录
[root@hadoop ~]#userdel lzh
[root@hadoop ~]#ll /home/
(2)删除用户和用户主目录,都删除
[root@hadoop ~]#useradd zhangsan
[root@hadoop ~]#ll /home/
[root@hadoop ~]#userdel -r zhangsan
[root@hadoop ~]#ll /home/
6.6 who 查看登录用户信息
1)基本语法
(1)whoami (功能描述:显示自身用户名称)
(2)who am i (功能描述:显示登录用户的用户名以及登陆时间)
2)实操练习
(1)显示自身用户名称
[root@hadoop ~]# whoami
(2)显示登录用户的用户名
[root@hadoop ~]# who am i
6.7usermod 修改用户
1)基本语法
usermod -g 用户组 用户名
2)选项说明
| 选项 | 功能 |
|---|
| -g | 修改用户的初始登录组,给定的组必须存在。默认组id是1。 |
3)实操练习
(1)将用户加入到用户组
[root@hadoop ~]# usermod -g root lzh
6.8 groupadd 新增组
1)基本语法
groupadd 组名
2)实操练习
(1)添加一个group1组
[root@hadoop ~]# groupadd group1
6.9 groupdel 删除组
1)基本语法
groupdel 组名
**2)**实操练习
(1)删除组
[root@hadoop ~]# groupdel group1
6.10 groupmod 修改组
1)基本语法
groupmod -n 新组名 老组名
1)选项说明
3)实操练习
(1)修改group2组名称为group3
[root@hadoop ~]# groupadd group2
[root@hadoop ~]# groupmod -n group3 group2
6.12 cat /etc/group 查看创建了哪些组
1)基本操作
[root@hadoop ~]# cat /etc/group
7.Linux查找文件
7.1find查找命令
find指令将从指定目录向下递归地遍历其各个子目录,将满足条件的文件显示在终端。
1)基本语法
find [搜索范围] [选项]
2)选项说明
| 选项 | 功能 |
|---|
| -name<查询方式> | 按照指定的文件名查找模式查找文件 |
| -user<用户名> | 查找属于指定用户名所有文件 |
| -size<文件大小> | 按照指定的文件大小查找文件 |
3)案例练习
(1)按文件名:根据名称查找/root下的.txt文件。
[root@hadoop ~]# find /root -name "*.txt"
(2)按拥有者:查找/root目录下,用户名称为root的文件
[root@hadoop ~]# find /root -user root
(3)按文件大小:在/目录下查找大于20M的文件(+n 大于 -n小于 n等于)
[root@hadoop ~]find / -size +20M
7.2 grep 过滤查找及“|”管道符
管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理
1)基本语法
grep 选项 查找内容 源文件
2)选项说明
3)案例练习
(1)查找某文件在第几行
[root@hadoop ~]# ls | grep -n xxx
8.Linux磁盘进程命令
8.1 df 查看磁盘空间使用情况
df: disk free 空余硬盘
1)基本语法
df 选项 (功能描述:列出文件系统的整体磁盘使用量,检查文件系统的磁盘空间占用情况)
2)选项说明
| 选项 | 功能 |
|---|
| -h | 以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示; |
3)案例实操
(1)查看磁盘使用情况
[root@hadoop ~]# df -h
8.2ps 查看当前系统进程状态
ps:process status 进程状态
1)基本语法
ps -aux | grep xxx (功能描述:查看系统中所有进程)
ps -ef | grep xxx (功能描述:可以查看子父进程之间的关系)
2)选项说明
| 选项 | 功能 |
|---|
| -a | 选择所有进程 |
| -u | 显示所有用户的所有进程 |
| -x | 显示没有终端的进程 |
3)功能说明
(1)ps -aux显示信息说明
USER:该进程是由哪个用户产生的
PID:进程的ID号
%CPU:该进程占用CPU资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位KB;
RSS:该进程占用实际物理内存的大小,单位KB;
TTY:该进程是在哪个终端中运行的。其中tty1-tty7代表本地控制台终端,tty1-tty6是本地的字符界面终端,tty7是图形终端。pts/0-255代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行、S:睡眠、T:停止状态、s:包含子进程、+:位于后台
START:该进程的启动时间
TIME:该进程占用CPU的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
(2)ps -ef显示信息说明
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
4)经验技巧
如果想查看进程的CPU占用率和内存占用率,可以使用aux;
如果想查看进程的父进程ID可以使用ef;
8.3 kill 终止进程
1)基本语法
kill [选项] 进程号 (功能描述:通过进程号杀死进程)
killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用)
2)选项说明
3)案例实操
(1)强制杀死6666进程
[root@hadoop~]# kill -9 6666
9.LinuxRPM
RPM 是Red-Hat Package Manager(红帽软件包管理器)的缩写,这一文件格式名称虽然打上了RedHat的标志,但是其原始是开放式的,包括OpenLinux、S.u.S.E.以及Turbo Linux等的分发版本都有采用,类似windows里面的setup.exe,可以算是公认的行业标准了。
9.1 RPM查询命令(rpm -qa)
1)基本语法
rpm -qa (功能描述:查询所安装的所有rpm软件包)
2)经验技巧
由于软件包比较多,一般都会采取过滤。rpm -qa | grep rpm软件包
3)案例实操
(1)查询xxx软件安装情况
[root@hadoop~]# rpm -qa |grep xxx
9.2RPM卸载命令(rpm -e)
1)基本语法
(1)rpm -e RPM软件包
(2) rpm -e --nodeps 软件包
2)选项说明
| 选项 | 功能 |
|---|
| -e | 卸载软件包 |
| --nodeps | 卸载软件时,不检查依赖。这样的话,那些使用该软件包的软件在此之后可能就不能正常工作了。 |
3)案例实操
(1)卸载xxx软件
[root@hadoop~]# rpm -e xxx.rpm
9.4 RPM安装命令(rpm -ivh)
1)基本语法
rpm -ivh RPM包全名
2)选项说明
| 选项 | 功能 |
|---|
| -i | -i=install,安装 |
| -v | -v=verbose,显示详细信息 |
| -h | -h=hash,进度条 |
| --nodeps | --nodeps,不检测依赖进度 |
3)案例实操
(1)安装xxx软件
[root@hadoop~]# rpm -ivh xxx.rpm
10.Linux YUM
YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装
**1)**基本语法
yum [选项] [参数]
**2)**选项说明
**3)**参数说明
| 参数 | 功能 |
|---|
| install | 安装rpm软件包 |
| update | 更新rpm软件包 |
| check-update | 检查是否有可用的更新rpm软件包 |
| remove | 删除指定的rpm软件包 |
| list | 显示软件包信息 |
| clean | 清理yum过期的缓存 |
| deplist | 显示yum软件包的所有依赖关系 |
**4)**案例实操实操
(1)采用yum方式安装wget
[root@hadoop ~]#yum -y install wget
二、Linux进阶-》Shell编程
1.课程导学
1.1什么是Shell
Shell是一个命令行解析器,它是用户使用 Linux 的桥梁。
1.2为什么要学Shell
1)大数据程序员:编写Shell程序管理大数据集群,掌握大数据集群的常用脚本编写(集群启动,关闭,状态等脚本编写)
2)后端程序员:根据工作需求,编写脚本对程序后台服务器进行维护
3)运维工程师:编写Shell脚本对服务器进行管理等
1.3查看Linux提供的解析器
[root@bigdata04 ~]# cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
[root@bigdata04 bin]# ll |grep bash
-rwxr-xr-x. 1 root root 964536 4月 1 2020 bash
lrwxrwxrwx. 1 root root 4 9月 14 15:55 sh -> bash
[root@bigdata04 bin]# echo $SHELL
/bin/bash
2.Shell初体验
2.1创建hello.sh文件
[root@bigdata04 shellTest]# touch hello.sh
2.2编辑脚本
[root@bigdata04 shellTest]# vim hello.sh
2.3注意:脚本以#!/bin/bash开头(指定解析器)
#!/bin/bash
echo "helloworld"
2.4脚本执行
基本语法
1)sh+脚本路径
2)直接脚本路径
3)实操练习
[root@bigdata04 shellTest]# sh hello.sh
[root@bigdata04 shellTest]# sh /root/shellTest/hello.sh
[root@bigdata04 shellTest]# ./hello.sh
[root@bigdata04 shellTest]# /root/shellTest/hello.sh
4)注意
sh+脚本路径本质是bash解析器帮你执行脚本,所以脚本本身不需要执行权限。路径直接执行本质是脚本需要自己执行,所以需要执行权限。
3.Shell变量
3.1系统变量
$HOME、$SHELL、$USER等
1)查看某系统变量
[root@bigdata04 ~]# echo $HOME
3.2用户自定义变量
1)基本语法
定义变量:变量=值
撤销变量:unset 变量
2)规则说明
(1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
(2)等号两侧不能有空格
(3)在bash中,变量默认类型都是字符串类型,无法直接进行数值运算。
(4)变量的值如果有空格,需要使用双引号或单引号括起来
3)实操练习
(1) 定义变量a=1
[root@bigdata04 ~]# a=1
(2)撤销变量a
[root@bigdata04 ~]# unset a
(3)bash默认类型为字符串,无法直接运算
[root@bigdata04 ~]# b=1+1
[root@bigdata04 ~]# echo $b
1+1
(4)变量的值如果有空格,需要使用双引号或单引号括起来
[root@bigdata04 ~]# c=i love you
bash: love: 未找到命令
[root@bigdata04 ~]# c="i love you"
(5)把变量提升为全局环境变量,给其他Shell程序使用
export 变量名
[root@bigdata04 ~]# vim hello.sh
在hello.sh中增加$d
#!/bin/bash
echo "hello"
echo $d
执行hello.sh
[root@bigdata04 testShell]# ./hello.sh
全局变量设置
[root@bigdata04 testShell]# export d
./helloworld.sh
3.3特殊变量
1) $n(功能描述:n为数字,$0代表该脚本名称,$1-$9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10})
实操练习
[root@bigdata04 testShell]# touch a.sh
[root@bigdata04 testShell]# vim a.sh
#!/bin/bash
echo "文件名=$0,第一个参数=$1,第二个参数=$2"
[root@bigdata04 testShell]# sh a.sh zhangsan lisi
2)$#(功能描述:获取所有输入参数个数,常用于循环)。
实操练习
[root@bigdata04 testShell]# vim a.sh
#!/bin/bash
echo "文件名=$0,第一个参数=$1,第二个参数=$2"
echo "参数个数=$#"
[root@bigdata04 testShell]# sh a.sh zhangsan lisi
3)$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
[root@bigdata04 testShell]# vim a.sh
#!/bin/bash
echo "文件名=$0,第一个参数=$1,第二个参数=$2"
echo "参数个数=$#"
echo "所有的参数=$*"
[root@bigdata04 testShell]# sh a.sh zhangsan lisi
4)$?(功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)
4.Shell运算
1)基本语法
“$((运算式))”或“$[运算式]”
2)实操练习
案例1:计算(2+2)*2的值
[root@bigdata04 testShell]# e=$[(2+2)*2]
[root@bigdata04 testShell]# echo $e
案例2:编写sum.sh计算2个数的和(从命令行传入)
[root@bigdata04 testShell]#touch sum.sh
[root@bigdata04 testShell]#vim sum.sh
#!/bin/bash
sum=$[($1+$2)]
echo $sum
5.Shell条件判断
1)基本用法
[ 判断条件 ](注意判断条件前后要有空格)
2)常用判断条件
(1)两个整数之间比较
| -lt 小于(less than) |
|---|
| -le 小于等于(less equal) |
| -eq 等于(equal) |
| -gt 大于(greater than) |
| -ge 大于等于(greater equal) |
| -ne 不等于(Not equal) |
| -a (and) |
| -o (or) |
(2)按照文件权限进行判断
| -r 有读的权限(read) |
|---|
| -w 有写的权限(write) |
| -x 有执行的权限(execute) |
(3)按照文件类型进行判断
| -f 文件存在并且是一个常规的文件(file) |
|---|
| -e 文件存在(existence) |
| -d 文件存在并是一个目录(directory) |
3)实操练习
案例1:判断1是否等于2
[root@bigdata04 ~]# [ 1 -eq 2 ]
[root@bigdata04 ~]# echo $?
1
案例2:判断hello.sh是否有写的权限
[root@bigdata04 ~]# [ -w hello.sh ]
[root@bigdata04 ~]# echo $?
0
案例3:判断hello.sh是否存在
[root@bigdata04 ~]# [ -e hello.sh ]
[root@bigdata04 ~]# echo $?
0
6.Shell流程控制
6.1if语句
1)基本语法
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
else
程序
fi
注意:[ 条件判断式 ],中括号和条件判断式之间必须有空格,if后要有空格
2)案例练习
案例1:编辑一个shell脚本,输入一个分数,大于60为及格,0-60为不及格,其余为输入有误。
[root@bigdata04 testShell]# touch if.sh
[root@bigdata04 testShell]# vim if.sh
#!/bin/bash
if [ $1 -ge 60 ]
then
echo "你及格了,很棒"
else
echo "没有及格,需要努力"
fi
6.2case语句
1)基本语法
case $变量名 in
"值1")
如果变量的值等于值1,则执行程序1
;;
"值2")
如果变量的值等于值2,则执行程序2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
注意事项:
(1)case行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
(2)双分号“;;”表示命令序列结束,相于java中的break。
(3)最后的“*)”表示默认模式,相当于java中的default。
2)实操练习
案例1:当命令行参数为1的时候,输出今天是周一,为2的时候输出今天是周二,其他情况输出other
#!/bin/bash
case $1 in
1)
echo 今天是周一;;
2)
echo 今天是周二;;
*)
echo other ;;
esac
6.3for循环
1)基本语法1
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
基本语法2
for 变量 in 值1 值2 值n
do
程序
done
2)实操练习
案例1:计算1-100的数求和
#!/bin/bash
for (( i=0;i<=100;i++ ))
do
sum=$[$sum+$i]
done
echo $sum
案例2:计算1-n求和,n为控制台录入
#!/bin/bash
for (( i=0;i<=$1;i++ ))
do
sum=$[$sum+$i]
done
echo $sum
案例3:打印输出所有参数
#!/bin/bash
for i in $*
do
echo "my name is $i"
done
6.4while循环
1)基本语法
while [ 条件判断式 ]
do
程序
done
2)案例练习
#!/bin/bash
sum=0
i=0
while [ $i -le 100 ]
do
sum=$[$sum+$i]
i=$[$i+1]
done
echo $sum
7.read读取控制台输入
1)基本语法
read(选项)(参数)
2)选项说明
| -p:指定读取值时的提示符; |
|---|
| -t:指定读取值时等待的时间(秒) |
参数
变量:指定读取值的变量名
3)实操练习
案例1:读取控制台两个数并求和
#!/bin/bash
read -p "请输入第一个数" a
read -p "请输入第二个数" b
sum=$[$a+$b]
echo "两个数的和为$sum"
8.Shell函数
Shell编程和其他编程语言一样,有系统函数,也可以自定义函数
8.1系统函数
8.1.1 basename
1)基本语法
basename [string / pathname] [suffix] (功能描述:basename命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。
选项:
suffix为后缀,如果suffix被指定了,basename会将pathname或string中的suffix去掉。
2)实操练习
[root@localhost testShell]# basename /root/testShell/case.sh
case.sh
[root@localhost testShell]# basename /root/testShell/case.sh .sh
case
8.1.2 dirname
1)基本语法
dirname 文件绝对路径 (功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分))
2)实操练习
[root@localhost testShell]# dirname /root/testShell/for.sh
/root/testShell
8.2自定义函数
1)基本语法
function 函数名(){
函数体
}
注意:必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先编译。
2)案例实操
案例1:编写getsum函数计算两个命令行输入数字的和
#!/bin/bash
function getsum(){
sum=$[$1+$2]
echo $sum
}
read -p "请输入第一个数: " n1;
read -p "请输入第二个数: " n2;
getsum $n1 $n2;
9.cut命令
cut的工作就是“剪”,负责在文件中剪切数据。
1)基本用法
cut [选项参数] 文件名
2)选项说明
| 选项 | 功能 |
|---|
| -f | 列号,提取第几列 |
| -d | 分隔符,按照指定分隔符分割列 |
| -c | 指定具体的字符 |
3)实操练习
案例1:切割出cut.txt文件第2列
[root@localhost testShell]# touch test.txt
[root@localhost testShell]# vim test.txt
疫 我
情 想
快 开
过 学
去 了
[root@localhost testShell]# cut -d " " -f 2 test.txt
案例2:过滤出test.txt中的"我"字
[root@localhost testShell]# cat test.txt |grep "我"| cut -d " " -f 2
10.Linux面试题
10.1 写出Linux常用命令,至少10个(百度)
10.2 shell脚本里如何检查一个文件是否存在并给出提示(百度)
10.3 请用指令找出当然文件夹(/home)下所有文本文件中包含有"cat"字符的文件的名称(金山)